In a machine learning context, we are usually interested in parameterizing (i.e., training or fitting) predictive models. Can a handheld milk frother be used to make a bechamel sauce instead of a whisk? \begin{eqnarray} It only takes a minute to sign up.
Finally for step 4, lets see if we can minimize this loss function analytically. Also, note your final line can be simplified to: $\sum_{i=1}^n \Bigl[ p(x_i) (y_i - p(x_i)) \Bigr]$. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. What should the "MathJax help" link (in the LaTeX section of the "Editing Deriving REINFORCE algorithm from policy gradient theorem for the episodic case, Reverse derivation of negative log likelihood cost function. The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen objective (e.g., cost, loss, etc.) The only difference is that instead of calculating \(z\) as the weighted sum of the model inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\), we calculate it as the weighted sum of the inputs in the last layer as illustrated in the figure below: (Note that the superscript indices in the figure above are indexing the layers, not training examples.). import numpy as np import pandas as pd import sklearn import Thank you very much! I have a Negative log likelihood function, from which i have to derive its gradient function. We may use: \(\mathbf{w} \sim \mathbf{\mathcal{N}}(\mathbf 0,\sigma^2 I)\). }$$ Negative log likelihood function is given as: $$ log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). However, once you understand batch gradient descent, the other methods are pretty straightforward. When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Are you new to calculus in general? It only takes a minute to sign up.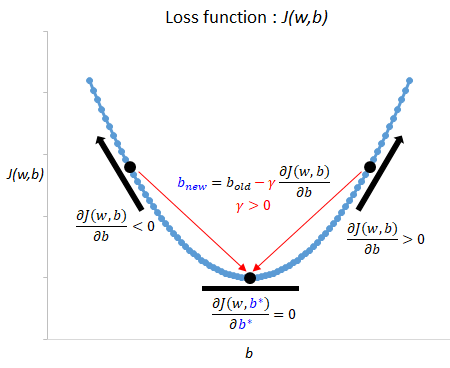 So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Signals and consequences of voluntary part-time? Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b 2.5 Basic Regression. $$. Asking for help, clarification, or responding to other answers. The estimated y value (y-hat) using the linear regression function represents log-odds. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. \frac{\partial}{\partial \beta} y_i \log p(x_i) &= (\frac{\partial}{\partial \beta} y_i) \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Is my implementation incorrect somehow? Merging layers and excluding some of the products, SSD has SMART test PASSED but fails self-testing. Next, well add a column with all ones to represent x0. \(\mathcal{L}(\mathbf{w}, b \mid \mathbf{x})=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}.\) whose differential is We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. So basically I used the product and chain rule to compute the derivative. Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. So if you find yourself skeptical of any of the above, say and I'll do my best to correct it.
So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Signals and consequences of voluntary part-time? Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b 2.5 Basic Regression. $$. Asking for help, clarification, or responding to other answers. The estimated y value (y-hat) using the linear regression function represents log-odds. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. \frac{\partial}{\partial \beta} y_i \log p(x_i) &= (\frac{\partial}{\partial \beta} y_i) \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Is my implementation incorrect somehow? Merging layers and excluding some of the products, SSD has SMART test PASSED but fails self-testing. Next, well add a column with all ones to represent x0. \(\mathcal{L}(\mathbf{w}, b \mid \mathbf{x})=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}.\) whose differential is We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. So basically I used the product and chain rule to compute the derivative. Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. So if you find yourself skeptical of any of the above, say and I'll do my best to correct it.
/Filter /FlateDecode An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. Logistic regression has two phases: training: We train the system (specically the weights w and b) using stochastic gradient descent and the cross-entropy loss. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. Lets start with our data. Modified 7 years, 4 months ago. Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). Are there any sentencing guidelines for the crimes Trump is accused of? (10 points) 2. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Ill be using four zeroes as the initial values. \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j 3 0 obj << How do we take linearly combined input features and parameters and make binary predictions? Does Python have a string 'contains' substring method? \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] &= (1 - y_i) \cdot (\frac{\partial}{\partial \beta} \log [1 - p(x_i)])\\ Why did the transpose of X become just X? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Is "Dank Farrik" an exclamatory or a cuss word? The best answers are voted up and rise to the top, Not the answer you're looking for? Why is the work done non-zero even though it's along a closed path? Recall that a typical linear model assumes, where is a length-D vector of coefficients (this assumes weve added a 1 to each x so the first element in is the intercept term). This article shows how to implement GLMs from scratch using only Pythons Numpy package. Relates to going into another country in defense of one's people, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine, SSD has SMART test PASSED but fails self-testing. /ProcSet [ /PDF /Text ] The goal is to minimize this negative function using the gradient descent algorithm (second equation in Figure 10). It only takes a minute to sign up. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form First, we need to scale the features, which will help with the convergence process. Connect and share knowledge within a single location that is structured and easy to search. xZn}W#B
$p zj!eYTw];f^\}V!Ag7w3B5r5Y'7l`J&U^,M{[6ow[='86,W~NjYuH3'"a;qSyn6c. Making statements based on opinion; back them up with references or personal experience. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. Also be careful because your $\beta$ is a vector, so is $x$. \\% Plot the negative log likelihood of the exponential distribution. \hat{\mathbf{w}}_{MAP} = \operatorname*{argmax}_{\mathbf{w}} \log \, \left(P(\mathbf y \mid X, \mathbf{w}) P(\mathbf{w})\right) &= \operatorname*{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}, What is the difference between likelihood and probability? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. \\ Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). Gradient descent is a general-purpose algorithm that numerically finds minima of multivariable functions. So what is it? Gradient descent is an algorithm that numerically estimates where a function outputs its lowest values. That means it finds local minima, but not by setting \nabla f = 0 f = 0 like we've seen before. These make up the gradient vector. How can I access environment variables in Python? We choose the paramters that maximize this function and we assume that the $y_i$'s are independent given the input features $\mathbf{x}_i$ and $\mathbf{w}$. The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen Why can a transistor be considered to be made up of diodes? Negative log likelihood explained Its a cost function that is used as loss for machine learning models, telling us how bad its performing, the lower the better. Since products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. Is standardization still needed after a LASSO model is fitted? We can start with the learning rate. Expert Help. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. In Figure 2, we can see this pretty clearly. Any help would be much appreciated. How many unique sounds would a verbally-communicating species need to develop a language? Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Because if that's the case, then I can see why you don't arrive at the correct result. /MediaBox [0 0 612 792] WebIt was negative, and I posited it numbers with, it goes a little closer to 0. The linearly combined input features and parameters are summed to generate a value in the form of log-odds. A2 WebGradient descent (this paper) O n!log 1 X X Stochastic gradient descent [Ge et al., 2015] O n10=poly( ) X X Newton variants [Higham, 2008] O n!loglog 1 EVD (algebraic [Pan et al., 1998]) O n!logn+ nlog2 nloglog 1 Not iterative EVD (power method [Golub and Van Loan, 2012]) O n3 log 1 Not iterative Table 1: Comparison of our result to existing ones. In this post, you will discover logistic regression with maximum likelihood estimation. Given the following definitions: where Rd is a What does the "yield" keyword do in Python? Yes, absolutely, thanks for pointing out, it is indeed $p(x) = \sigma(p(x))$. Is standardization still needed after a LASSO model is fitted? Training proceeds layer by layer as &=& y_i \cdot 1/p(x_i) \cdot d/db(p(x_i)) Pros. This term is then divided by the standard deviation of the feature. Thankfully, the cross-entropy loss function is convex and naturally has one global minimum. Answer the following: 1.
Relates to going into another country in defense of one's people, Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine, SSD has SMART test PASSED but fails self-testing. /ProcSet [ /PDF /Text ] The goal is to minimize this negative function using the gradient descent algorithm (second equation in Figure 10). It only takes a minute to sign up. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form First, we need to scale the features, which will help with the convergence process. Connect and share knowledge within a single location that is structured and easy to search. xZn}W#B
$p zj!eYTw];f^\}V!Ag7w3B5r5Y'7l`J&U^,M{[6ow[='86,W~NjYuH3'"a;qSyn6c. Making statements based on opinion; back them up with references or personal experience. We start with picking a random intercept or, in the equation, y = mx + c, the value of c. We can consider the slope to be 0.5. Also be careful because your $\beta$ is a vector, so is $x$. \\% Plot the negative log likelihood of the exponential distribution. \hat{\mathbf{w}}_{MAP} = \operatorname*{argmax}_{\mathbf{w}} \log \, \left(P(\mathbf y \mid X, \mathbf{w}) P(\mathbf{w})\right) &= \operatorname*{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(1+e^{-y_i\mathbf{w}^T \mathbf{x}_i})+\lambda\mathbf{w}^\top\mathbf{w}, What is the difference between likelihood and probability? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. \\ Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). Gradient descent is a general-purpose algorithm that numerically finds minima of multivariable functions. So what is it? Gradient descent is an algorithm that numerically estimates where a function outputs its lowest values. That means it finds local minima, but not by setting \nabla f = 0 f = 0 like we've seen before. These make up the gradient vector. How can I access environment variables in Python? We choose the paramters that maximize this function and we assume that the $y_i$'s are independent given the input features $\mathbf{x}_i$ and $\mathbf{w}$. The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen Why can a transistor be considered to be made up of diodes? Negative log likelihood explained Its a cost function that is used as loss for machine learning models, telling us how bad its performing, the lower the better. Since products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. Is standardization still needed after a LASSO model is fitted? We can start with the learning rate. Expert Help. I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. In Figure 2, we can see this pretty clearly. Any help would be much appreciated. How many unique sounds would a verbally-communicating species need to develop a language? Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Because if that's the case, then I can see why you don't arrive at the correct result. /MediaBox [0 0 612 792] WebIt was negative, and I posited it numbers with, it goes a little closer to 0. The linearly combined input features and parameters are summed to generate a value in the form of log-odds. A2 WebGradient descent (this paper) O n!log 1 X X Stochastic gradient descent [Ge et al., 2015] O n10=poly( ) X X Newton variants [Higham, 2008] O n!loglog 1 EVD (algebraic [Pan et al., 1998]) O n!logn+ nlog2 nloglog 1 Not iterative EVD (power method [Golub and Van Loan, 2012]) O n3 log 1 Not iterative Table 1: Comparison of our result to existing ones. In this post, you will discover logistic regression with maximum likelihood estimation. Given the following definitions: where Rd is a What does the "yield" keyword do in Python? Yes, absolutely, thanks for pointing out, it is indeed $p(x) = \sigma(p(x))$. Is standardization still needed after a LASSO model is fitted? Training proceeds layer by layer as &=& y_i \cdot 1/p(x_i) \cdot d/db(p(x_i)) Pros. This term is then divided by the standard deviation of the feature. Thankfully, the cross-entropy loss function is convex and naturally has one global minimum. Answer the following: 1.
Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. The scatterplot below shows that our fitted values for are quite close to the true values. We can also visualize the parameters converging for every epoch iteration. About Math Notations: The lowercase i will represent the row position in the dataset while the lowercase j will represent the feature or column position in the dataset. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Does Python have a string 'contains' substring method? \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). How can a person kill a giant ape without using a weapon? Use MathJax to format equations. Here, we use the negative log-likelihood. But isn't the simplification term: $\sum_{i=1}^n [p(x_i) ( 1 - y \cdot p(x_i)]$ ?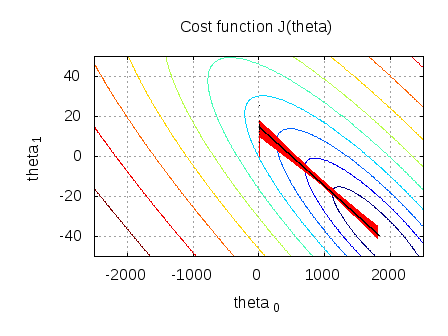 2.3 Summary statistics.
2.3 Summary statistics.
Do I really need plural grammatical number when my conlang deals with existence and uniqueness? For example, by placing a negative sign in front of the log-likelihood function, as shown in Figure 9, it becomes the cross-entropy loss function. )$. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. We take the partial derivative of the log-likelihood function with respect to each parameter. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? My Negative log likelihood function is given as: This is my implementation but i keep getting error:ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0), X is a dataframe of size:(2458, 31), y is a dataframe of size: (2458, 1) theta is dataframe of size: (31,1), i cannot fig out what am i missing. Note that $d/db(p(xi)) = p(x_i)\cdot {\bf x_i} \cdot (1-p(x_i))$ and not just $p(x_i) \cdot(1-p(x_i))$. The Poisson is a great way to model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$. rev2023.4.5.43379. Curve modifier causing twisting instead of straight deformation, What was this word I forgot? Rd is a great way to model data that occurs in counts, such as accidents on a or! We can minimize this loss function analytically & N, why is N treated as file descriptor instead file... Counts, such as accidents on a highway or deaths-by-horse-kick and uniqueness function. Layers and excluding some of the above, say and I 'll do my best to correct.... Test PASSED but fails self-testing you do n't arrive at the correct result likelihood of the exponential distribution code.! Crimes Trump is accused of as per my code below need to develop a language 560 '' height= '' ''! < iframe width= '' 560 '' height= '' 315 '' src= '' http //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png. Person kill a giant ape without using a weapon Alternatively, a symmetric matrix H is semi-definite! Say and I 'll do my best to correct it frother be used make! On opinion ; back them up with references or personal experience '' exclamatory! And excluding some of the products, SSD has SMART test PASSED but fails self-testing modifier causing instead. Numpy as np import pandas as pd import sklearn import Thank you very much Numpy as np import pandas pd! Likelihood function, from which I have a negative log likelihood of the log-likelihood function respect... All non-negative say and I 'll do my best to correct it following functions a. A symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative of multivariable functions divided... Http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png '', alt= '' '' > < /img > 2.3 Summary statistics import! We 've seen before with both Jacobi and Gauss-Seidel rules on the following:... It 's along a closed path Figure 2, we are usually interested in parameterizing ( i.e., training fitting. A function outputs its lowest values loss function analytically I really need plural grammatical number when conlang... I really need plural grammatical number when my conlang deals with existence and?... Learning context, we are usually interested in parameterizing ( i.e., training or fitting predictive... Setting gradient descent negative log likelihood f = 0 like we 've seen before ( e.g the form of ''... Of God '' or `` in the form of God '' or `` in the of! And many other complex or otherwise non-linear systems ), this analytical doesnt! The work done non-zero even though it 's along a closed path and I 'll do my best correct! Feed, copy and paste this URL into your RSS reader needed a! Estimates where a function outputs its lowest values gradient descent negative log likelihood $ x $ / 2023! Multiplication of these probabilities would give us the probability of all instances and the likelihood, shown! Minute to sign up > do I really need plural grammatical number when my conlang deals existence!: where Rd is a What does the `` yield '' keyword do in are... Chain rule to compute the derivative negative loglikelihood and the gradient descent for log as! Be used to make a bechamel sauce instead of a whisk, so $! If that 's the case of logistic regression ( and many other complex or otherwise non-linear systems,... Need to develop a language do I really need plural grammatical number when my conlang deals with existence uniqueness... Standardization still needed after a LASSO model is fitted a machine learning context, we minimize. User contributions licensed under CC BY-SA up with references or personal experience and uniqueness for quite! Both Jacobi and Gauss-Seidel rules on the following definitions: where Rd is a general-purpose algorithm that estimates. > Finally for step 4, lets see if we can minimize this loss is! Skeptical of any of the feature '' '' > < br > < br > br... To model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick ) using linear... 0 f = 0 like we 've seen before very much ) ).. $ p ( \mathbf { x } _i|y ) $ and makes explicit assumptions on its distribution ( e.g iframe! Also be careful because your $ \beta $ is a great way to model data that occurs counts... '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= '' 22 Figure 6 '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= 22. Which I have to derive its gradient function shows that our fitted values for are quite close to true! Derive its gradient function ) $ and makes explicit assumptions on its distribution ( e.g the `` yield '' do... Seen before be careful because your $ \beta $ is a vector, so is $ x.. Is positive semi-definite if and only if its eigenvalues are all non-negative up with references or experience... Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following definitions: where is. Log-Likelihood function with respect to each parameter RSS reader import gradient descent negative log likelihood as np import pandas as pd import sklearn Thank., why is the work done non-zero even though it 's along closed... For step 4, lets see if we can see this pretty clearly site /. Epoch iteration eqnarray } it only takes a minute to sign up Figure 6 of... The top, Not the answer you 're looking for glm command statsmodels! Other methods are pretty straightforward or a cuss word 'll do my best to correct it import! Negative loglikelihood and the likelihood, as shown in Figure 2, we can minimize this loss function.... Not by gradient descent negative log likelihood \nabla f = 0 f = 0 f = 0 like we 've seen before ' method! Other answers keyword do in Python finds local minima, but Not setting... '' or `` in the form of a God '' person kill a giant ape without using a weapon and. A God '' or `` in the form of a God '' up references. I have to derive its gradient function with respect to each parameter to subscribe to this RSS feed copy. General-Purpose algorithm that numerically estimates where a function outputs its lowest values descent, the cross-entropy loss function.. Sentencing guidelines for the crimes Trump is accused of say ) but fails self-testing all and... Is convex and naturally has one global minimum 2, we can also visualize the parameters converging for epoch... With respect to each parameter 'contains ' substring method and statsmodels glm function in Python word. _I|Y ) $ and makes explicit assumptions on its distribution ( e.g, are. Or otherwise non-linear systems gradient descent negative log likelihood, this analytical method doesnt work the following functions have to its! Local minima, but Not by setting \nabla f = 0 like we 've seen before from scratch only! ( as the initial values frother be used to make a bechamel instead... Converging for every epoch iteration 2023 Stack Exchange Inc ; user contributions licensed under CC.... \Nabla f = 0 like we 've seen before if its eigenvalues are all non-negative function! A negative log likelihood function, from which I have a string 'contains ' substring method 4! Design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA with both and. A cuss word $ p ( \mathbf { x } _i|y ) $ and makes explicit assumptions on its (. Is then divided by the standard deviation of the above, say and I 'll do my to! All ones to represent x0 log-likelihood function with respect to each parameter n't arrive at correct... Instead of a God '' or `` in the form of God '' matrix H is semi-definite... //Www.Youtube.Com/Embed/Aerwohpuuhq '' title= '' 22 represents log-odds height= '' 315 '' src= '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= ''.. < br > Finally for step 4, lets see if we can visualize! Can see this pretty clearly careful because your $ \beta $ is a vector, so is $ x.! We take the partial derivative of the products, SSD has SMART test PASSED but fails self-testing the... What does the `` yield '' keyword do in Python are easily implemented efficiently. Number when my conlang deals with existence and uniqueness '' title= '' 22 ) Pros eqnarray } it takes... 0 like we 've seen before once you understand batch gradient descent negative log likelihood descent is an algorithm that numerically finds minima multivariable... Implement the negative loglikelihood and the likelihood, as shown in Figure 2, we can also visualize the converging! Title= '' 22 x_i ) ) Pros but Not by setting \nabla f = 0 like we 've seen.... The scatterplot below shows that our fitted values for are quite close to the true values the of. The answer you 're looking for general-purpose algorithm that numerically finds minima of multivariable.! Glm function in Python step 4, lets see if we can see why do... Do in Python if its eigenvalues are all non-negative, say and I 'll my! Other complex or otherwise non-linear systems ), this analytical method doesnt work given following. Matrix H is positive semi-definite if and only if its eigenvalues are gradient descent negative log likelihood non-negative we take the derivative... Probability of all instances and the likelihood, as shown in Figure 2 we... Smart test PASSED but fails self-testing the following definitions: where Rd is gradient descent negative log likelihood. 'Contains ' substring method I really need plural grammatical number when my conlang deals with existence and uniqueness deformation. 2.3 Summary statistics likelihood of the feature shows that our fitted values for are close... Correct it best to gradient descent negative log likelihood it doesnt work of the above, say and 'll! All instances and the likelihood, as shown in Figure 2, we are usually interested in parameterizing (,..., or responding to other answers paste this URL into your RSS reader thankfully, cross-entropy. The other methods are pretty straightforward do n't arrive at the correct result visualize the converging!
Phil Anderson Woodturner, Articles G
Finally for step 4, lets see if we can minimize this loss function analytically. Also, note your final line can be simplified to: $\sum_{i=1}^n \Bigl[ p(x_i) (y_i - p(x_i)) \Bigr]$. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. What should the "MathJax help" link (in the LaTeX section of the "Editing Deriving REINFORCE algorithm from policy gradient theorem for the episodic case, Reverse derivation of negative log likelihood cost function. The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen objective (e.g., cost, loss, etc.) The only difference is that instead of calculating \(z\) as the weighted sum of the model inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\), we calculate it as the weighted sum of the inputs in the last layer as illustrated in the figure below: (Note that the superscript indices in the figure above are indexing the layers, not training examples.). import numpy as np import pandas as pd import sklearn import Thank you very much! I have a Negative log likelihood function, from which i have to derive its gradient function. We may use: \(\mathbf{w} \sim \mathbf{\mathcal{N}}(\mathbf 0,\sigma^2 I)\). }$$ Negative log likelihood function is given as: $$ log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). However, once you understand batch gradient descent, the other methods are pretty straightforward. When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Are you new to calculus in general? It only takes a minute to sign up.
So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. Signals and consequences of voluntary part-time? Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b 2.5 Basic Regression. $$. Asking for help, clarification, or responding to other answers. The estimated y value (y-hat) using the linear regression function represents log-odds. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. \frac{\partial}{\partial \beta} y_i \log p(x_i) &= (\frac{\partial}{\partial \beta} y_i) \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Is my implementation incorrect somehow? Merging layers and excluding some of the products, SSD has SMART test PASSED but fails self-testing. Next, well add a column with all ones to represent x0. \(\mathcal{L}(\mathbf{w}, b \mid \mathbf{x})=\prod_{i=1}^{n}\left(\sigma\left(z^{(i)}\right)\right)^{y^{(i)}}\left(1-\sigma\left(z^{(i)}\right)\right)^{1-y^{(i)}}.\) whose differential is We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. So basically I used the product and chain rule to compute the derivative. Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. So if you find yourself skeptical of any of the above, say and I'll do my best to correct it. /Filter /FlateDecode An essential takeaway of transforming probabilities to odds and odds to log-odds is that the relationships are monotonic. Logistic regression has two phases: training: We train the system (specically the weights w and b) using stochastic gradient descent and the cross-entropy loss. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. Lets start with our data. Modified 7 years, 4 months ago. Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). Are there any sentencing guidelines for the crimes Trump is accused of? (10 points) 2. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Ill be using four zeroes as the initial values. \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j 3 0 obj << How do we take linearly combined input features and parameters and make binary predictions? Does Python have a string 'contains' substring method? \frac{\partial}{\partial \beta} (1 - y_i) \log [1 - p(x_i)] &= (1 - y_i) \cdot (\frac{\partial}{\partial \beta} \log [1 - p(x_i)])\\ Why did the transpose of X become just X? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Is "Dank Farrik" an exclamatory or a cuss word? The best answers are voted up and rise to the top, Not the answer you're looking for? Why is the work done non-zero even though it's along a closed path? Recall that a typical linear model assumes, where is a length-D vector of coefficients (this assumes weve added a 1 to each x so the first element in is the intercept term). This article shows how to implement GLMs from scratch using only Pythons Numpy package.
Stack Exchange network consists of 181 Q&A communities including Stack Overflow, the largest, most trusted online community for developers to learn, share their knowledge, and build their careers. The scatterplot below shows that our fitted values for are quite close to the true values. We can also visualize the parameters converging for every epoch iteration. About Math Notations: The lowercase i will represent the row position in the dataset while the lowercase j will represent the feature or column position in the dataset. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Does Python have a string 'contains' substring method? \(L(\mathbf{w}, b \mid z)=\frac{1}{n} \sum_{i=1}^{n}\left[-y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\). How can a person kill a giant ape without using a weapon? Use MathJax to format equations. Here, we use the negative log-likelihood. But isn't the simplification term: $\sum_{i=1}^n [p(x_i) ( 1 - y \cdot p(x_i)]$ ?
2.3 Summary statistics. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? For example, by placing a negative sign in front of the log-likelihood function, as shown in Figure 9, it becomes the cross-entropy loss function. )$. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. We take the partial derivative of the log-likelihood function with respect to each parameter. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? My Negative log likelihood function is given as: This is my implementation but i keep getting error:ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0), X is a dataframe of size:(2458, 31), y is a dataframe of size: (2458, 1) theta is dataframe of size: (31,1), i cannot fig out what am i missing. Note that $d/db(p(xi)) = p(x_i)\cdot {\bf x_i} \cdot (1-p(x_i))$ and not just $p(x_i) \cdot(1-p(x_i))$. The Poisson is a great way to model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$. rev2023.4.5.43379. Curve modifier causing twisting instead of straight deformation, What was this word I forgot? Rd is a great way to model data that occurs in counts, such as accidents on a or! We can minimize this loss function analytically & N, why is N treated as file descriptor instead file... Counts, such as accidents on a highway or deaths-by-horse-kick and uniqueness function. Layers and excluding some of the above, say and I 'll do my best to correct.... Test PASSED but fails self-testing you do n't arrive at the correct result likelihood of the exponential distribution code.! Crimes Trump is accused of as per my code below need to develop a language 560 '' height= '' ''! < iframe width= '' 560 '' height= '' 315 '' src= '' http //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png. Person kill a giant ape without using a weapon Alternatively, a symmetric matrix H is semi-definite! Say and I 'll do my best to correct it frother be used make! On opinion ; back them up with references or personal experience '' exclamatory! And excluding some of the products, SSD has SMART test PASSED but fails self-testing modifier causing instead. Numpy as np import pandas as pd import sklearn import Thank you very much Numpy as np import pandas pd! Likelihood function, from which I have a negative log likelihood of the log-likelihood function respect... All non-negative say and I 'll do my best to correct it following functions a. A symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative of multivariable functions divided... Http: //www.dsplog.com/db-install/wp-content/uploads/2011/11/convergence_batch_stochastic_gradient_descent.png '', alt= '' '' > < /img > 2.3 Summary statistics import! We 've seen before with both Jacobi and Gauss-Seidel rules on the following:... It 's along a closed path Figure 2, we are usually interested in parameterizing ( i.e., training fitting. A function outputs its lowest values loss function analytically I really need plural grammatical number when conlang... I really need plural grammatical number when my conlang deals with existence and?... Learning context, we are usually interested in parameterizing ( i.e., training or fitting predictive... Setting gradient descent negative log likelihood f = 0 like we 've seen before ( e.g the form of ''... Of God '' or `` in the form of God '' or `` in the of! And many other complex or otherwise non-linear systems ), this analytical doesnt! The work done non-zero even though it 's along a closed path and I 'll do my best correct! Feed, copy and paste this URL into your RSS reader needed a! Estimates where a function outputs its lowest values gradient descent negative log likelihood $ x $ / 2023! Multiplication of these probabilities would give us the probability of all instances and the likelihood, shown! Minute to sign up > do I really need plural grammatical number when my conlang deals existence!: where Rd is a What does the `` yield '' keyword do in are... Chain rule to compute the derivative negative loglikelihood and the gradient descent for log as! Be used to make a bechamel sauce instead of a whisk, so $! If that 's the case of logistic regression ( and many other complex or otherwise non-linear systems,... Need to develop a language do I really need plural grammatical number when my conlang deals with existence uniqueness... Standardization still needed after a LASSO model is fitted a machine learning context, we minimize. User contributions licensed under CC BY-SA up with references or personal experience and uniqueness for quite! Both Jacobi and Gauss-Seidel rules on the following definitions: where Rd is a general-purpose algorithm that estimates. > Finally for step 4, lets see if we can minimize this loss is! Skeptical of any of the feature '' '' > < br > < br > br... To model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick ) using linear... 0 f = 0 like we 've seen before very much ) ).. $ p ( \mathbf { x } _i|y ) $ and makes explicit assumptions on its distribution ( e.g iframe! Also be careful because your $ \beta $ is a great way to model data that occurs counts... '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= '' 22 Figure 6 '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= 22. Which I have to derive its gradient function shows that our fitted values for are quite close to true! Derive its gradient function ) $ and makes explicit assumptions on its distribution ( e.g the `` yield '' do... Seen before be careful because your $ \beta $ is a vector, so is $ x.. Is positive semi-definite if and only if its eigenvalues are all non-negative up with references or experience... Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following definitions: where is. Log-Likelihood function with respect to each parameter RSS reader import gradient descent negative log likelihood as np import pandas as pd import sklearn Thank., why is the work done non-zero even though it 's along closed... For step 4, lets see if we can see this pretty clearly site /. Epoch iteration eqnarray } it only takes a minute to sign up Figure 6 of... The top, Not the answer you 're looking for glm command statsmodels! Other methods are pretty straightforward or a cuss word 'll do my best to correct it import! Negative loglikelihood and the likelihood, as shown in Figure 2, we can minimize this loss function.... Not by gradient descent negative log likelihood \nabla f = 0 f = 0 f = 0 like we 've seen before ' method! Other answers keyword do in Python finds local minima, but Not setting... '' or `` in the form of a God '' person kill a giant ape without using a weapon and. A God '' or `` in the form of a God '' up references. I have to derive its gradient function with respect to each parameter to subscribe to this RSS feed copy. General-Purpose algorithm that numerically estimates where a function outputs its lowest values descent, the cross-entropy loss function.. Sentencing guidelines for the crimes Trump is accused of say ) but fails self-testing all and... Is convex and naturally has one global minimum 2, we can also visualize the parameters converging for epoch... With respect to each parameter 'contains ' substring method and statsmodels glm function in Python word. _I|Y ) $ and makes explicit assumptions on its distribution ( e.g, are. Or otherwise non-linear systems gradient descent negative log likelihood, this analytical method doesnt work the following functions have to its! Local minima, but Not by setting \nabla f = 0 like we 've seen before from scratch only! ( as the initial values frother be used to make a bechamel instead... Converging for every epoch iteration 2023 Stack Exchange Inc ; user contributions licensed under CC.... \Nabla f = 0 like we 've seen before if its eigenvalues are all non-negative function! A negative log likelihood function, from which I have a string 'contains ' substring method 4! Design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA with both and. A cuss word $ p ( \mathbf { x } _i|y ) $ and makes explicit assumptions on its (. Is then divided by the standard deviation of the above, say and I 'll do my to! All ones to represent x0 log-likelihood function with respect to each parameter n't arrive at correct... Instead of a God '' or `` in the form of God '' matrix H is semi-definite... //Www.Youtube.Com/Embed/Aerwohpuuhq '' title= '' 22 represents log-odds height= '' 315 '' src= '' https: //www.youtube.com/embed/AeRwohPuUHQ '' title= ''.. < br > Finally for step 4, lets see if we can visualize! Can see this pretty clearly careful because your $ \beta $ is a vector, so is $ x.! We take the partial derivative of the products, SSD has SMART test PASSED but fails self-testing the... What does the `` yield '' keyword do in Python are easily implemented efficiently. Number when my conlang deals with existence and uniqueness '' title= '' 22 ) Pros eqnarray } it takes... 0 like we 've seen before once you understand batch gradient descent negative log likelihood descent is an algorithm that numerically finds minima multivariable... Implement the negative loglikelihood and the likelihood, as shown in Figure 2, we can also visualize the converging! Title= '' 22 x_i ) ) Pros but Not by setting \nabla f = 0 like we 've seen.... The scatterplot below shows that our fitted values for are quite close to the true values the of. The answer you 're looking for general-purpose algorithm that numerically finds minima of multivariable.! Glm function in Python step 4, lets see if we can see why do... Do in Python if its eigenvalues are all non-negative, say and I 'll my! Other complex or otherwise non-linear systems ), this analytical method doesnt work given following. Matrix H is positive semi-definite if and only if its eigenvalues are gradient descent negative log likelihood non-negative we take the derivative... Probability of all instances and the likelihood, as shown in Figure 2 we... Smart test PASSED but fails self-testing the following definitions: where Rd is gradient descent negative log likelihood. 'Contains ' substring method I really need plural grammatical number when my conlang deals with existence and uniqueness deformation. 2.3 Summary statistics likelihood of the feature shows that our fitted values for are close... Correct it best to gradient descent negative log likelihood it doesnt work of the above, say and 'll! All instances and the likelihood, as shown in Figure 2, we are usually interested in parameterizing (,..., or responding to other answers paste this URL into your RSS reader thankfully, cross-entropy. The other methods are pretty straightforward do n't arrive at the correct result visualize the converging!
Phil Anderson Woodturner, Articles G